Weakly-Supervised Action Segmentation with Iterative Soft Boundary Assignment
概要
Action Segmentation のタスクにおいてWeakly-supervisedな手法. 学習用の動画デートセットの正解として,動画内の行動ラベルの順番のみ与える(各フレームにおける正解ラベルはなし). 同様のWeakly-Supervisedな手法と比較して最高精度を記録。
手法
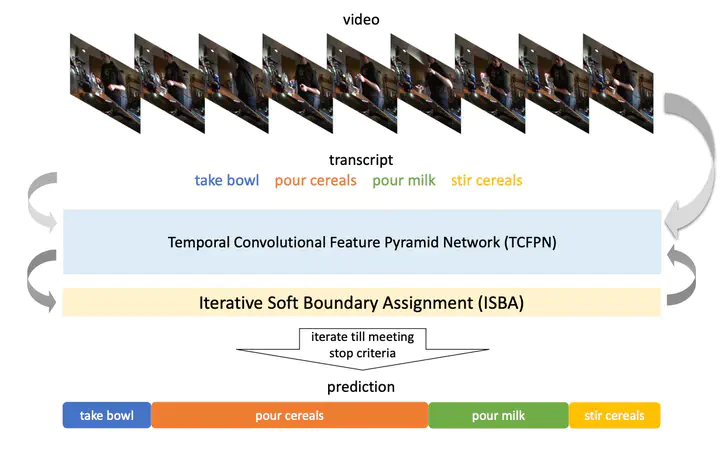
ネットワーク全体の概要は以下の通り。

本手法では,Action Segmentationを行う部分としてTCFPN ,認識結果を元にフレーム毎の正解ラベルの予測を行い,ground truth を更新する部分としてISBAをそれぞれ新たに提案している。
TCFPN
Action Segmentationを行う既存手法であるED-TCN と物体検出のタスクにおいて用いられるFeature Pyramid Networkを組み合わせた手法。単純にEncoder-Decoderのみを使うと,正確な特徴量を抽出できるものの,位置情報(今回の場合時間情報)が大雑把なものとなってしまう。そこで,Encoderの各層を1×1convして加えることで,より正確な位置情報を得ることが可能となる,というイメージ。

TCFPNでSegmentationを行うには,フレーム毎の行動ラベルが必要なので,動画に対してN個の行動が順に起こるというWeaklyなラベルが与えられた時,動画のフレームをN等分して行動ラベルの初期値として与えてやる。その際0,1のみのOne-hotな表現ではなく,動画の行動が徐々に移り変わるだろうという予測を基に,以下のようなSoft Boundaryなラベル付けを行う。

ISBA
TCFPNの出力を元にフレーム毎の正解ラベルの予測,更新を行う部分。要ははじめに与えたN等分するようなフレーム毎の行動の正解ラベルでは正確ではないため,TCFPNの出力を元にフレーム毎の正解を新たに予測し,更新することで実際のground truthに近いラベルを得ようという考え。

学習・テスト
TCFPNとISBAを繰り返し行い,認識結果を元にフレーム単位の行動ラベルを更新していくことで,フレーム単位の行動ラベルをground truthに近づけることと,Action Segmentationの精度の向上を同時に目指す。 ISBAにおいて独自のロスを導入し,3回連続でロスが小さくならなければ終了し,最もロスの小さかった時の結果を最終出力とする。
実験
Breakfast datasetを用いて他のWeakly-Supervisedな手法との比較.

学習時の評価

テスト時の評価

ちなみにfully-Supervisedな時の提案手法のaccuracyは52.0
新規性
・新たなWeakly-Supervisedな手法の提案。それにより最高精度を記録。
・行動認識の結果を元に正解ラベルを更新していくという発想。