
論文ゆる要約
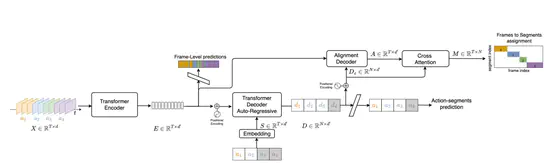
Unified Fully and Timestamp Supervised Temporal Action Segmentation via Sequence to Sequence Translation
Few-shot Learning においてTransormerを用いた局所の表現学習方法を提案。

Temporal-Relational CrossTransformers for Few-Shot Action Recognition
CrossTransformerを応用したFew-Shotの行動認識手法の提案。
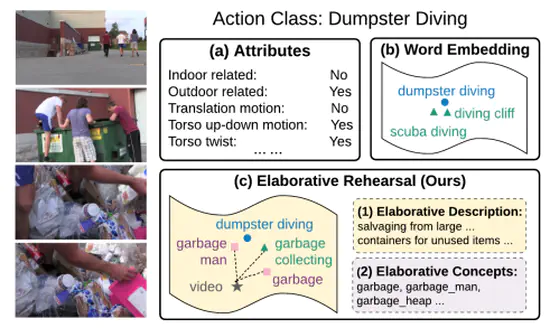
Elaborative Rehearsal for Zero-shot Action Recognition
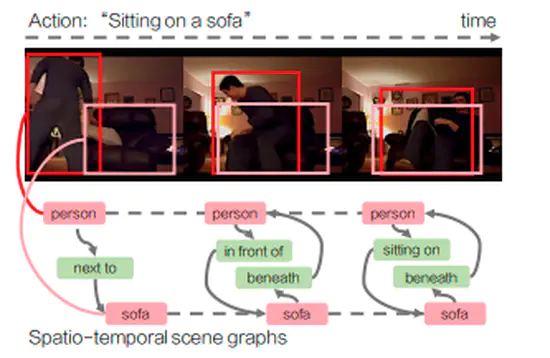
シーングラフ生成のタスクで既存のVisualGenomeデータセットにおける実験考察をもとに,新たにLSTMを用いた手法を提案。
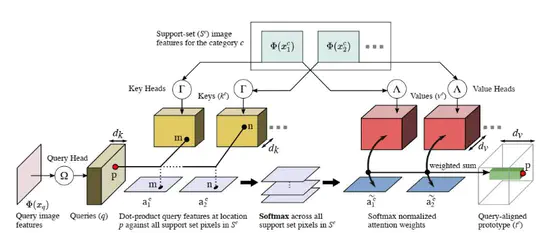
CrossTransformers: spatially-aware few-shot transfer
Few-shot Learning においてTransormerを用いた局所の表現学習方法を提案。
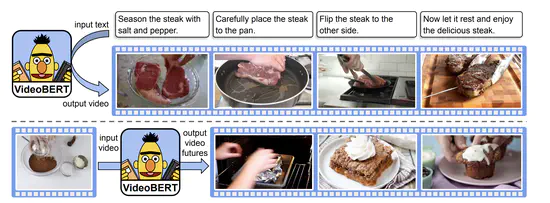
VideoBERT: A Joint Model for Video and Language Representation Learning
多くのモデルでVisionとLanguageでネットワークをそれぞれ用意して同時に学習させていた部分を,Bertを応用することでマルチモーダルに事前学習させる方法。
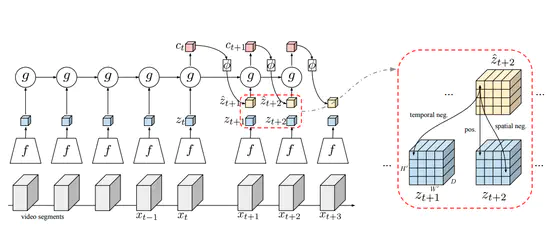
Video Representation Learning by Dense Predictive Coding
Predictive Codingで用いた手法を動画にも適用した論文。動画の次の潜在表現を回帰で予測させてあげて,相互情報量の最大化を目指す。
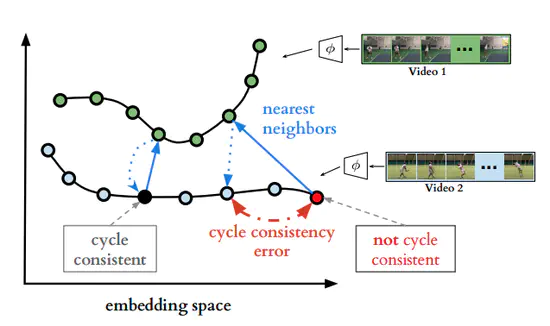
Temporal Cycle-Consistency Learning
異なる動画においても,同じ動作の場合特徴空間上で近くなるように学習させることで,似た動作の動画同士を同期できるようなマッチングを実現。
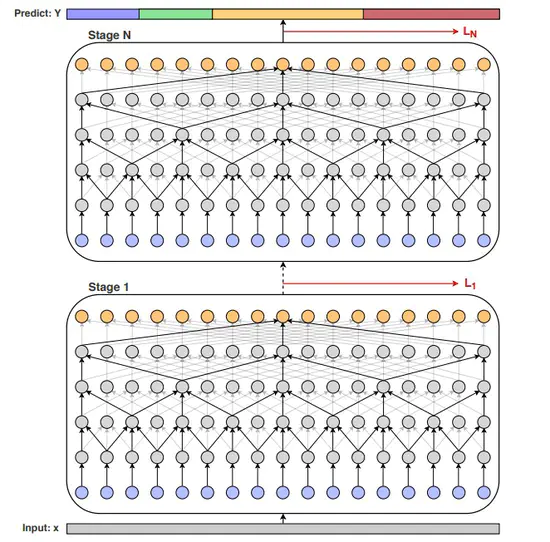
MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation
行動認識のタスクにおいて,Temporal Convolutional Networksを複数重ねるMulti-TCNの提案。
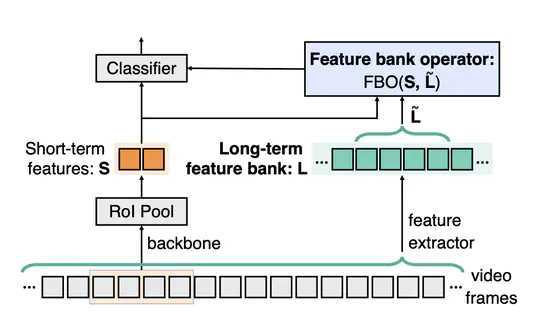
Long-Term Feature Banks for Detailed Video Understanding
3DCNNでは4秒近くにおける時系列情報しか捉えられない。そこでよりLongTermな情報と組み合わせて考えることでVideoRecognitionの精度が上がりましたよという論文。

Graphical Contrastive Losses for Scene Graph Parsing
シーングラフの生成において従来モデルの課題点を指摘した上で,それを改善するための新たなロスを提案し,SoTAを達成。
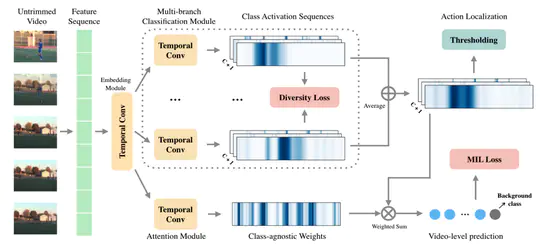
Completeness Modeling and Context Separation for Weakly Supervised Temporal Action Localization
Predictive Codingで用いた手法を動画にも適用した論文。動画の次の潜在表現を回帰で予測させてあげて,相互情報量の最大化を目指す。
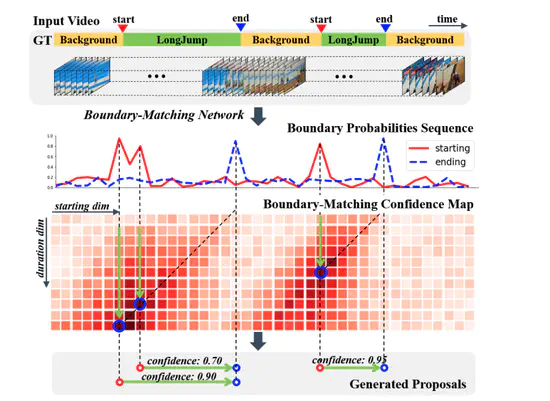
BMN: Boundary-Matching Network for Temporal Action Proposal Generation
Temporal action proposalのタスク。従来のような始点終点予測とは別に,Proposalの始点と長さを表すヒートマップを作成する。
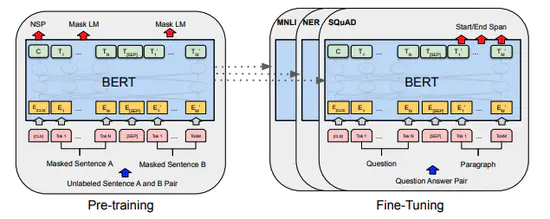
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
言語の事前学習によって,自然言語分野の複数のタスクにおいてSoTAを達成。
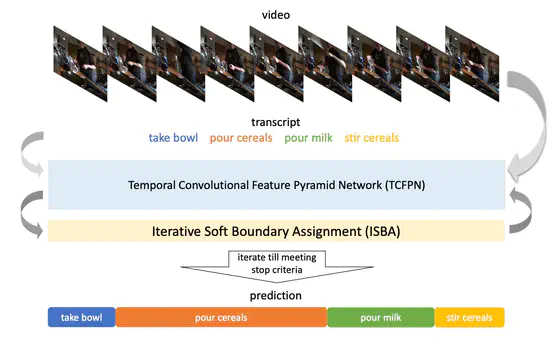
Weakly-Supervised Action Segmentation with Iterative Soft Boundary Assignment
Action Segmentation のタスクにおいてWeakly-supervisedな手法. 学習用の動画デートセットの正解として,動画内の行動ラベルの順番のみ与える(各フレームにおける正解ラベルはなし).
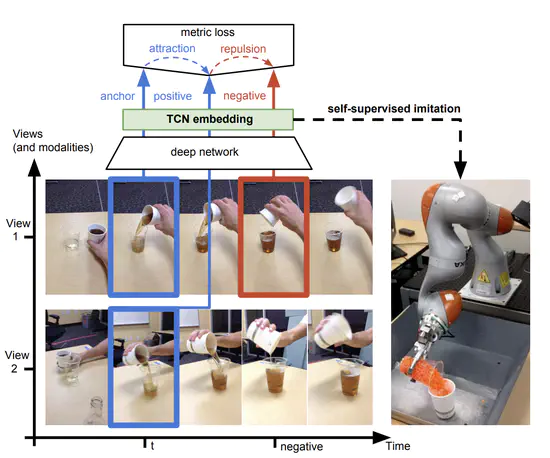
Time-Contrastive Networks: Self-Supervised Learning from Video
Action recognitionにおけるSelf-supervisedな事前学習方法の提案。
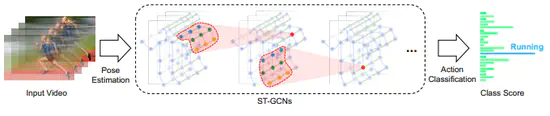
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
時空間方向のグラフ畳み込みを利用したSkeleton-basedな行動認識手法を提案。
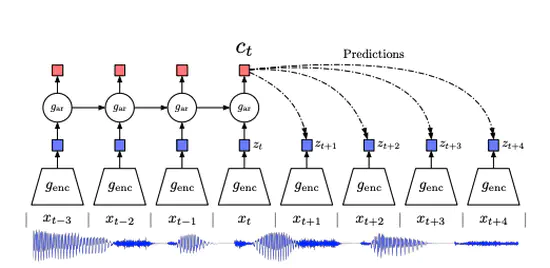
Representation Learning with Contrastive Predictive Coding
画像や音声における新しい表現学習の方法を提案。エンコーダーとGRUを組み合わせてGRUが次のエンコーダの出力を予測して,その相互情報量の最大化によって良い特徴表現を獲得する。
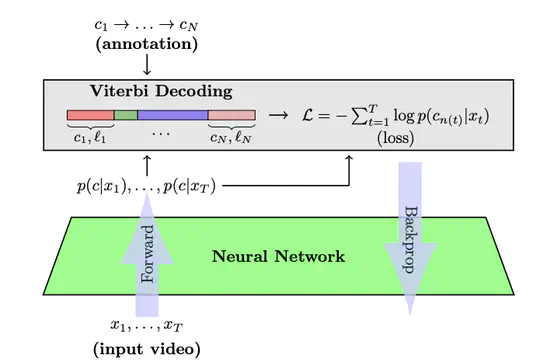
NeuralNetwork-Viterbi: A Framework for Weakly Supervised Video Learning
クラスラベルの遷移順のみのWeaklyなラベルを用いたAction Segmentation. Viterbi algorism を用いた方法を提案。
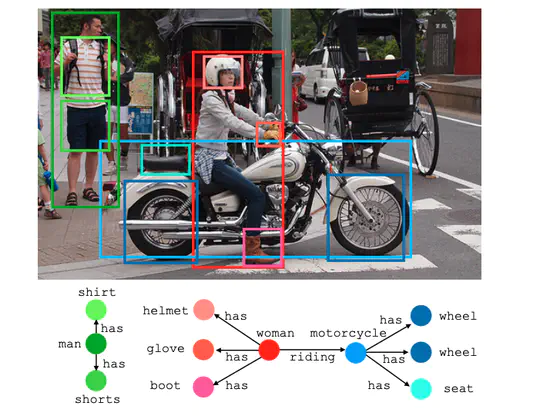
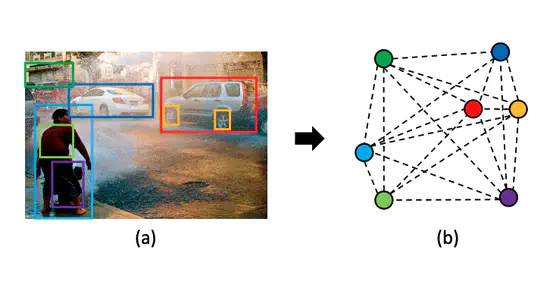
Neural Motifs: Scene Graph Parsing with Global Context
シーングラフ生成のタスクで既存のVisualGenomeデータセットにおける実験考察をもとに,新たにLSTMを用いた手法を提案。
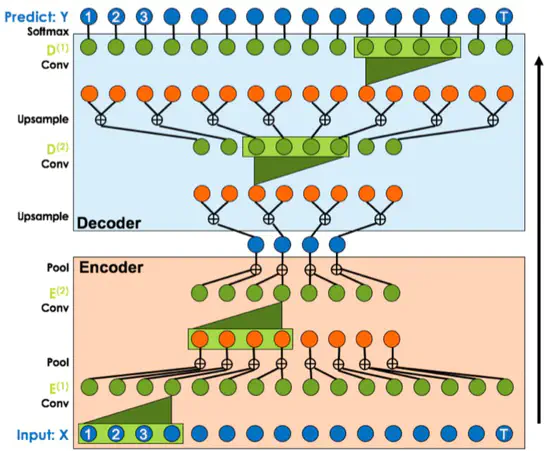
Temporal Convolutional Networks for Action Segmentation and Detection
詳細な行動認識のタスクにおいて、長期的な時系列情報を考慮するように畳み込みを行って認識を行うネットワークであるTemporal Convolutional Networkの提案.
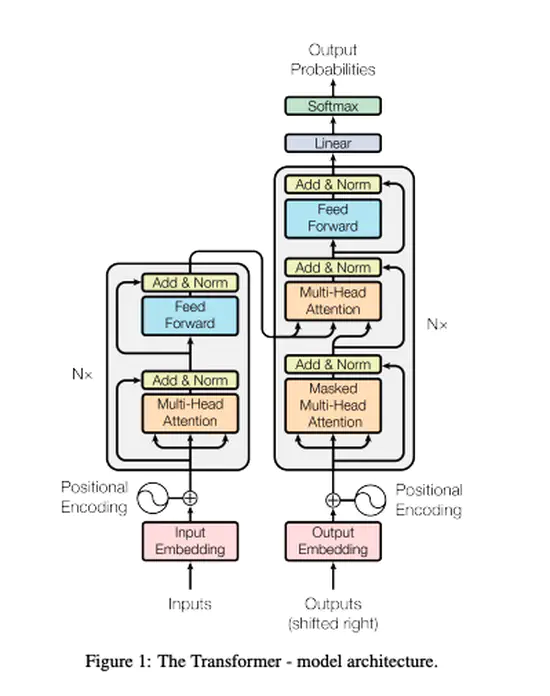
Attention is all you need
機械翻訳用のネットワークの提案。従来LSTMやGRUや畳み込みを主に用いていた自然言語の処理だが,アテンションのみを用いて単語間の関連性を考慮するような手法。
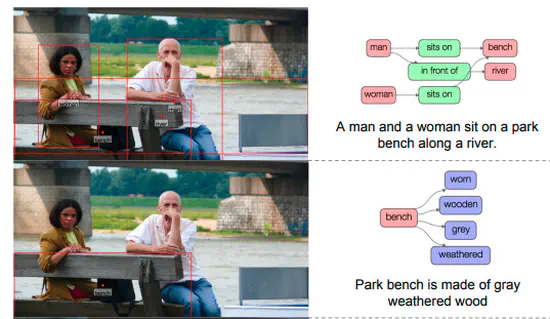
Visual Genome : Connecting Language and Vision Using Crowdsourced Dense Image Annotations
画像をもとにしたシーングラフやそれに関連したVQA等のラベルがついたVisual Genome データセットを作成。
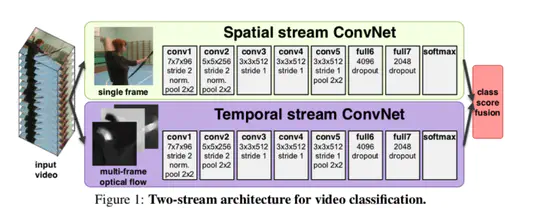
Two-Stream Convolutional Networks for Action Recognition in Videos
空間情報(静止画)と時間情報( フレーム間の動き)をそれぞれ畳み込んだ結果を統合することによる行動認識の手法を提案.