VideoBERT: A Joint Model for Video and Language Representation Learning
Publication
In CVPR 2019
概要
Vision and Language において,多くのモデルでVisionとLanguageでネットワークをそれぞれ用意して同時に学習させていた部分を,Bertを応用することでマルチモーダルに事前学習させる方法を提案。基本的にはBertのMask穴埋め問題をLanguage+Visionに拡張したもの。

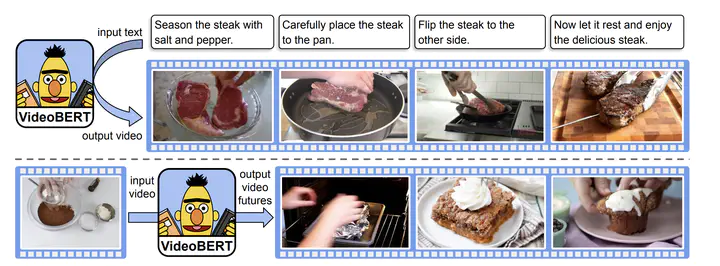
Downstreamのタスクとしては入力テキスト情報に対応したビデオフレームの出力や,入力ビデオの次におきうるアクションのビデオ出力等が挙げられる。
手法
ネットワーク全体の概要は以下の通り。

マスク穴埋め問題
ランダムで入力をマスクして,出力を予測させることでSelf-supervisedに学習するのはBertと一緒。違いとして,文章同士で入力ではなく,文章と対応するビデオのセットでの入力となる。ビデオ側のトークンはクラスタリングで定義し,4階層✖️12次元の計20736次元の階層的Kmeansによって分類し,言語側と同じくクロスエントロピーをロスとして学習。

実験
様々なDown Streamタスクでの比較。
Action classification

Video captioning


新規性
BertのようにSelf-supervisedな事前学習方法の提案によって大きなデータセット規模での学習を可能とし,精度の向上
コメント
Videoの入力があいまいなイメージ。Bertへの入力としてどのようなルールでフレームを選んでくるかは難しい問題に感じる。