Video Representation Learning by Dense Predictive Coding
Type
Publication
In ICCV 2019
概要
Predictive Codingで用いた手法を動画にも適用した論文。動画の次の潜在表現を回帰で予測させてあげて,相互情報量 の最大化を目指す。

手法
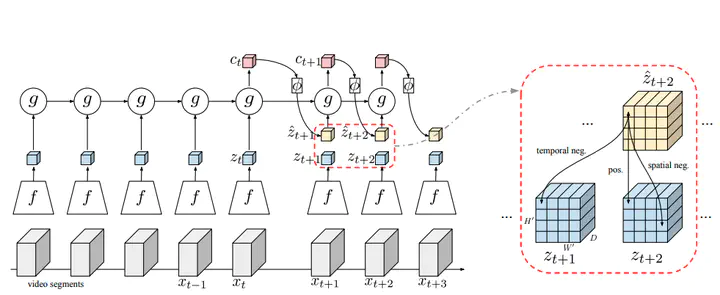
全体としての考え方はPredictive Codingと一緒。ただし今回は動画を入力として扱うので,単純にフレームごとに系列データとして扱っていく。

PositiveペアとNegativeペアによるMetric Learning。NegativeとしてはTemporalとSpatialがあり,フレーム内での同じ位置でも時間情報が違ったらNegativeとして遠ざけるよう学習する(背景に依存して動画全体として変化の少ない特徴表現となることを避けるため?)。
実験


新規性
相互情報量最大化の考え方を動画にも応用。