Unified Fully and Timestamp Supervised Temporal Action Segmentation via Sequence to Sequence Translation
概要
Task
アクションセグメンテーション
Input
各フレームに対して、行動ラベルが一種類与えられている動画。
Output
一般的にはフレーム毎に行動ラベルの予測結果を返すのに対し、行動ラベルのシーケンス(Transcriptと呼ぶ)とタイムスタンプ(Durationと呼ぶ)を別々に得て、セグメントレベルでの行動予測結果を返すことで、OverSegmentation(予測結果のブレがおきる)の問題を解決する。
Data
以下の2パターンを検証
- 教師あり(全てのフレームに行動ラベルあり)
- 弱教師あり(各Transcriptに属するフレームが1つずつのみ与えられている)
提案手法

ステップ
-
(a) : 一般的なSegmentationModelではOverSegmentationの問題が発生しやすく、後段で処理が必要。
-
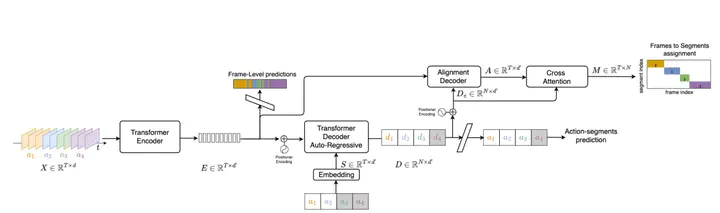
(b) : そこでTransformeベースのseq2seqモデルを適用し、Decoderの出力としてTranscriptとDurationを同時に得ることを考える。ただし、以下の2点の要因から、このモデル構造単体では機能しない。
- NLPと違い、非常に長い類似したフレーム入力に対して、短い行動出力シーケンスが求められる点。
- NPLと違い、データセットの規模が非常に小さく、扱える学習データが少ない点。
-
(c) : そこで、(a)のEncoderの出力をDecoderの入力として追加することで、デコーダでは異なる行動に対してより識別性の高い特徴を学習できる。これによりTranscriptでは改善を得るが、Durationについては以前精度が悪いままである。
-
(d) : そこで、Decoderでの直接のDuration出力はあきらめる。DecoderではあくまでTranscriptを得ることを目的とし、DurationについてはEncoderの出力も同時に活用することを考える。
-
(e) : Encoderで得たフレーム単位のクラス予測値とDecoderの出力との間で相互アテンションをとって、最終的なセグメントレベルでの行動予測結果を返す。
損失関数
- Encoder
通常のACtionSegmentationと同様、CrossEntropyLossを採用。 - Decoder
こちらもセグメント単位でのCrossEntropyLossを用いる。
実験
Dataset
- Breakfast
- 50salads
- GTEA
Result

コメント
弱教師学習でseq2seqを用いた2Branch(Transcript+Duration)手法がでてきていたものが、transformerベースのseq2seqとなったというイメージ。 ActionSegmentationのタスクでTransformerを利用していく中で、この論文でも述べているようにデータの少なさ+非常に長い類似したフレーム入力をどう扱っていくかが焦点になりそう。