Type
Publication
In NeurIPS 2014
概要
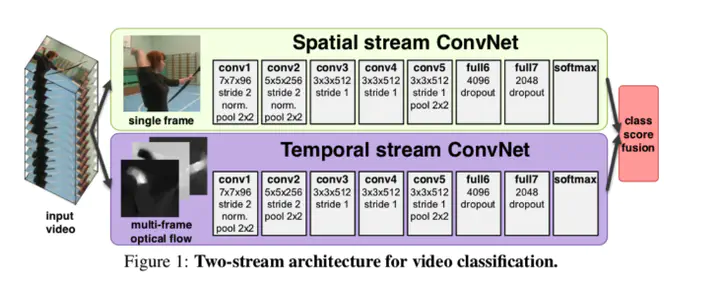
Spatial stream ConvNet(以後Spatial Conv)とTemporal stream ConvNet(以後Temporal Conv)の組み合わせ. Spatial Convでは各フレームの静止画(RGB画像)を入力して畳み込み、空間情報の抽出によるクラス分類. Temporal Convでは各フレームのオプティカルフローを入力して畳み込み、動き情報の抽出によるクラス分類. 下図のように,Spatial Convにおける1つの入力フレームに対して,Temporal ConvではそのフレームからNフレーム分のオプティカルフローを用いる。(RGBとオプティカルフローの入力が1:N)。 最終的な結果は、それぞれのネットワークのクラスの確率分布を統合し、最も高確率のクラスを出力.
Temporal Convにおいて、オプティカルフローは各フレームにおいてそれぞれ X,Y 方向に2次元配列として入力. よって、入力動画のRGBフレーム数がTの時、入力するオプティカルフローのフレーム数は2NT
手法

実験
UCF-101、HMDB-51データセットを用いてハンドクラフト特徴量を用いた行動認識(IDT等)と比較.
UCF-101データセット

HMDB-501

またSpatial Conv、Temporal Convそれぞれ単独で用いた場合とも比較.

UCF-101においては最も高精度. HMDB-51においてはハンドクラフトの方が高精度の場合も
新規性
・当時はハンドクラフト特徴量による認識が主流の中、深層学習を用いた手法.
・オプティカルフローを用いることで動画の時系列情報を捉えようとするアプローチ