概要
詳細な行動認識のタスクにおいて、動画の各フレームから抽出した特徴を用いて、長期的な時系列情報を考慮するように畳み込みを行って認識を行うネットワークであるTemporal Convolutional Network(以後TCN)の提案.
2種類のTCN , Encoder-Decoder TCN(以後ED-TCN) とDilated TCNを提案している.
手法
提案した両方のTCNにおいて、入力は各フレームから何かしらのCNN(Resnet,VGG等)を用いて抽出した特徴量を時系列順に並べたものであり、出力としては行動クラス結果が各フレームごとに出力される.
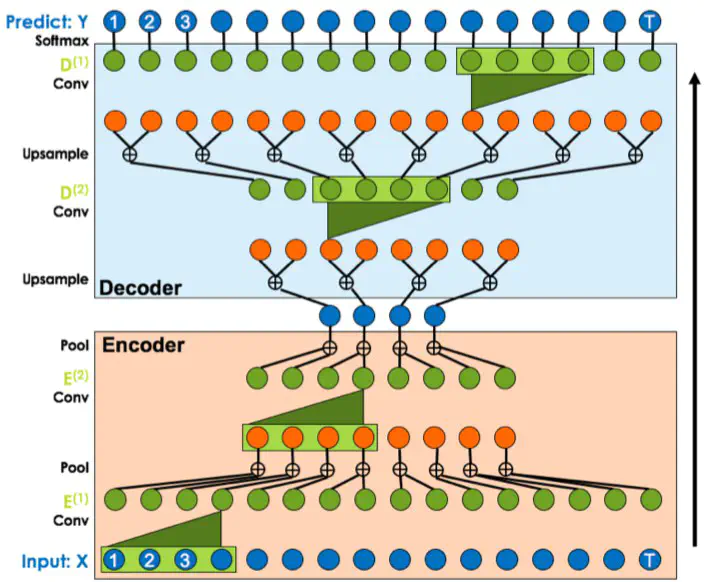
ED-TCN
エンコーダとデコーダを組み合わせたTCN. エンコーダで畳み込み+MaxPoolingを行うことで時系列を考慮した特徴抽出、その後デコーダで畳み込み+アップサンプリングを行うことで各フレームごとの行動クラス確率分布を得る.

Dilated-TCN
時系列の畳み込みとしてDilated Convolutionを用いた手法. Dilated Convolutionとは簡単に説明すると、入力の間隔を空けて(間を0とみなす)畳み込みを行うこと(d=1なら間隔なし、d=2なら間隔1、d=4なら間隔3). dの値をどんどん(本論文では指数関数的に)大きくしていったDilated Convolution層を重ねることで、より長期的な時系列の範囲で特徴抽出を行うことが可能となる. またスキップコネクションの導入で層を深くすることを可能に。

実験
50salads、MERL Shopping、GTEAの3種のデータセットを用いて、Spatial CNN等との比較


新規性
・各層ごとに同時に処理を行うため、入力フレーム数が増えても処理時間に影響をあまり与えない.
→フレームごとに処理を行うLSTM等と比較して高速な処理
・3Dconvは動画全体(数フレーム分)に対して1つの行動クラスの出力であるのに対し、TCNでは各フレームごとに行動クラスの出力が可能