Type
Publication
In 2018
概要
画像や音声における新しい表現学習の方法を提案。エンコーダーとGRUを組み合わせてGRUが次のエンコーダの出力を予測して,その相互情報量の最大化によって良い特徴表現を獲得する。

手法
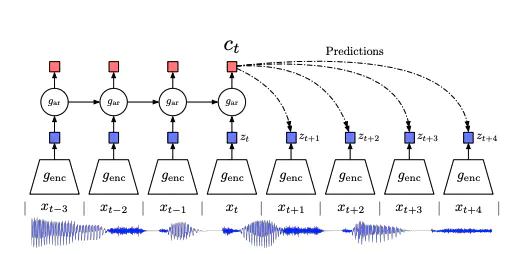
下図は音声入力の例。

GRUの出力が次の潜在表現を回帰・予測し,その相互情報量の最大化を目指すことによって良い特徴表現を得る。
ロス
NCEベースのロスを使用し,同じペアは近づけるように,ランダムにサンプルしたペアを遠ざけるよう学習。
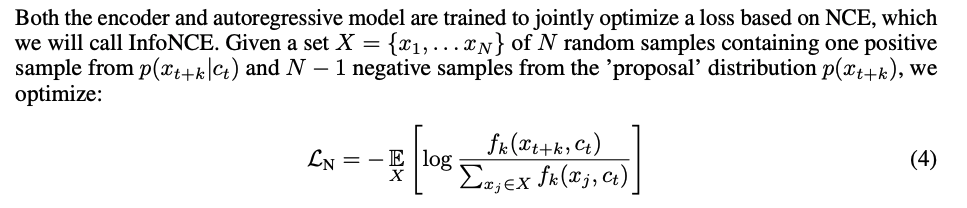
画像の場合
画像の場合そのままでは系列データにできないので,パッチごとにずらしていくことで系列データとして扱う。

実験
画像

言語

t-SNEによる音声表現の可視化

新規性
系列データにおいて次の潜在表現を予測し,相互情報量の最大化を目的にすることによる良い表現の獲得。