概要
シーングラフ生成のタスクで既存のVisualGenomeデータセットにおける実験考察をもとに,新たにLSTMを用いた手法を提案。

シーングラフの作成における考察
VisualGenomeを用いたシーングラフ生成の過程において,以下の2つの特徴があったと主張。
⓵ Objectの情報からRelationを更新することはRelationを予測する上で有効であるが,逆はそうではない。
下図は,右下に書かれてる四角の中の右半分の情報(Head=始点のObject,Tail=終点のObject,Edge=Relation)を用いて残りの左半分を予測したときのtopK/精度を示したもの。

見ると,headやtailからedgeを推測する際の精度が高いのに対し,edgeからhead, tailを予測するのは非常に難しくなっているのがわかる。
既存手法ではobjectとrelationの相互関係性に注目し,relationからobject情報を更新していたが,この操作にはあまり意味がないことを主張している。
⓶ 半分以上の画像において,一枚の中に複数回以上登場する同一の関係性(Motif)が存在している
動物と手足の関係や,木のように1つではなく大量に存在している物が写っている際,同じ関係性のMotifは何度も登場する可能性が高い。これらについて調査したところ,半分以上の画像においてこのような反復の関係性が確認された。

手法
今までのGraphConvを使った手法(Graph-RCNNとか)と違いLSTMを用いた手法(下図)。

構造としては,物体領域検出,物体クラス分類,関係性抽出の3段階構造。(B=BoundingBox, O=CLasslabel, R=Relation)
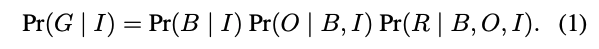
Objectcontext予測のあとにEdgecontext予測を持ってきているのは,上記の考察における⓵の理由に基づいている。 以下分けてみていく。

⓵ BoundingBox
BoundingBoxの出力にはFaster-RCNNを利用。Faster-RCNNの出力はboundingboxの他に領域における特徴ベクトルと仮のクラスラベル(次のステップで更新していく)。
⓶ Objects
biLSTMを用いて⓵で得た仮のクラスラベルを更新していく。得たBoundingBoxで得た結果を系列情報として順番にbiLSTMに入力し,最終的なクラスラベルの予測を行う。各層の入力として⓵のクラスラベルの他に,前の入力におけるLSTMの最終出力(クラスのone-hot)を用いる。
⓷ Relations
同様にbiLSTMを用いたedge情報の予測。入力として⓶で得たクラスのone-hotと,⓶のLSTMの隠れ層の出力を用いる。 最後に得た出力同士の全ての組み合わせを考えていき,関係性なしラベルを含んだエッジのラベルを予測させる。⓵で得たboundingbox,⓶で得たクラスラベル,⓷で得たEdgeの関係性ラベルを組み合わせて,最終的にシーングラフが作成できる。
実験
VisualGenomeを用いて評価。
[Scene Graph Detection] … ラベル情報なしでBBox, Object, Relation 全て予測
[Scene Graph Classification] … BBoxラベルありでObject, Relation 予測
[Predicate Classification] … BBox, Objectラベルありで Relation 予測

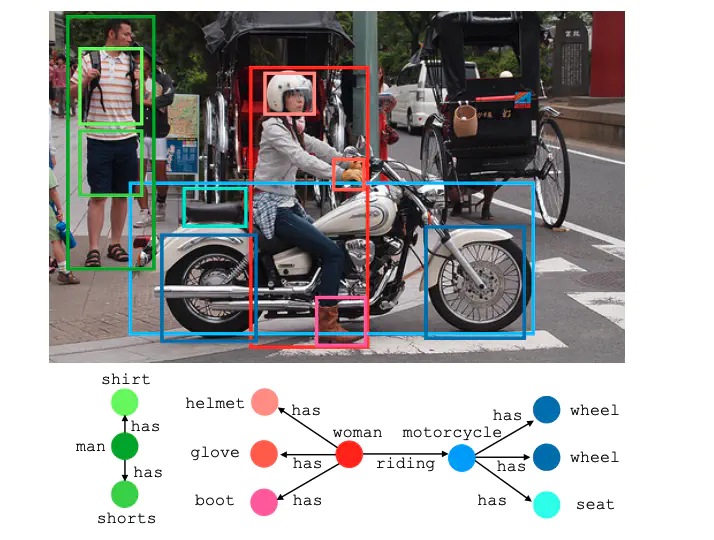
生成例

新規性
LSTMを用いた手法