Type
Publication
In NAACL 2019
概要
Bi-directional な Transformer を用いて,自然言語分野における新たな事前学習手法を提案。言語の事前学習によって,自然言語分野の複数のタスクにおいてSoTAを達成。
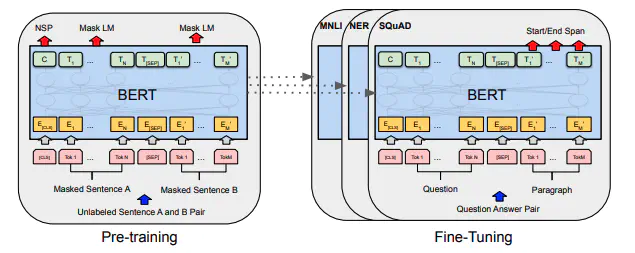
手法
MLMとNSPという二つのタスクを解かせてトランスフォーマのエンコーダ側を事前学習。
トランスフォーマで文章生成する際は,結局リカレントモデルと同じくそれ以前の単語の情報しか見れないという制約があるため,その制約を予め違う形でかけてPretrainしようというのがMLM。
単一の文章における単語の関連性による出現確率についてだけでなく,2つの文章を比較させることによって文章全体としてより良い特徴表現を得ようということを目的としているのがNSP.

Masked Language Model
入力の単語を予めいくつかマスキングしてしまい穴埋め問題を溶かせることによって,マスキングした部分の単語を前後の文脈の理解から復元させるタスク。入力シーケンスのうち,15%をランダムに選んでその部分の予測を行う。選んだ部分のうち80%はマスキング,10%は別の単語に置き換え,残りの10%はそのままの単語として入力させている。前後の文脈を考慮した特徴量抽出を行うことが目的。
Next Sentence Prediction
2つの文章を並べて入力してあげて,2文目が1文目の次に来る文かどうかを予測するタスク。2つの文章を比較して予測結果を返すため,文章全体として良い特徴表現を得ることが期待できる。

実験

新規性
新たな事前学習の枠組み。
様々なタスクに転用するだけで精度向上。