Type
Publication
In NeurIPS 2017
概要
機械翻訳用のネットワーク,トランスフォーマーの提案。従来LSTMやGRU等のリカレントネットワークや,畳み込みを主に用いていた自然言語の処理だが,アテンションのみを用いて単語間の関連性を考慮するような手法。
手法
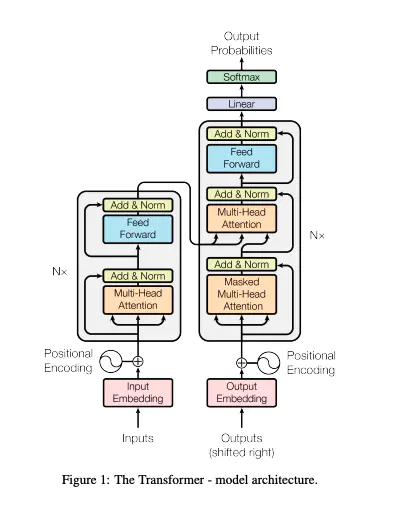
ネットワーク全体の概要は以下の通り。

エンコーダ・デコーダ共に,この手法のキモとなるMulti-Head Attentionを残差接続したものを複数層重ねた構造になっている。 図中の Inputsは翻訳前言語の原文, Outputsは学習時においてGroundTruth・推論時はBeginning of sentence,Output Probabilitiesにおいて翻訳した文章を得る。
アテンションの構造
アテンションの構造は以下のScaled Dot-Product Attention. 元の入力バッチからQ(Query),K(Key),V(Value)の3つを新たに用意して,そのうちQとKを用いて元のValueに掛け合わせるような重みマップ(Attention Map)のようなものを作成してあげる。

単純にAttentionではなくMulti-Headと表現されているのは,このアテンション計算の際にh分割して計算したのち,最後にまたコンカットしていることを指している。(多分計算コストの削減?精度的な寄与も関係あるかも)

既存手法に対する優位性
畳み込みとかリカレントネットワークに比べて長い時系列情報を見れるよねという話。あとリカレントネットワークは前の情報を引き継いで随時計算するのに対し,アテンションは一気に計算できるので,計算速度も全然早い。

実験

新規性
アテンションのみによる新たなネットワークの提案。
State of the art の更新。