Action Genome: Actions as Composition of Spatio-temporal Scene Graphs
概要
Visual Genomeの動画版のデータセット。またFeature Banksを用いた手法の提案。

手法
データセット
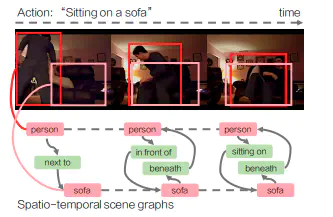
データセットのラベル内容としては動画中のActionの領域とそのCaption,またVisualGenomeのようなSceneGraphが与えられている。

動画内の各Actionに関して,Actionを均等な時間間隔で分割した際の5フレームを抽出し,その5フレームにおけるシーングラフのラベルを作成。上記の例では1つの動画で4つのアクションが起きているため,4✖️5の合計20フレーム分のシーングラフが存在する。
他のデータセットとの比較としては以下の通り。

動画から各Actionを抽出するAction Recognitionのタスクを考える。同グループの以前の研究であるFeature Banksをベースラインとして用いている。従来のように抽出した3DCNN特徴に加えて,今回のラベルによって得られるシーングラフを予測させてobjectとrelationshipsを捉えたfeatured map を同様にFeature bank として長期の時系列情報として保持することで,行動の分類を行っている。

実験
提案手法の評価。シーングラフ の利用によって精度の向上を確認。

既存のシーングラフ生成モデルをActionGenomeに適用した際の精度。既存の手法は画像ベースの手法のため精度も低く,動画用に改善の余地ありとのこと。

新規性
動画用のシーングラフを提案。シーングラフを用いたActionRecognitionの手法。
コメント
公開されたら触ってみたい。