Bianca Blog
Bianca Blog
PaperSummaries
BlogPosts
Works
0
Elaborative Rehearsal for Zero-shot Action Recognition
シーングラフ生成のタスクで既存のVisualGenomeデータセットにおける実験考察をもとに,新たにLSTMを用いた手法を提案。
Shizhe Chen
,
Dong Huang
PDF
Temporal-Relational CrossTransformers for Few-Shot Action Recognition
CrossTransformerを応用したFew-Shotの行動認識手法の提案。
Toby Perrett
,
Alessandro Masullo
PDF
Code
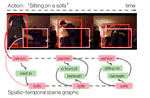
Action Genome: Actions as Composition of Spatio-temporal Scene Graphs
Visual Genomeの動画版のデータセット。
Jingwei Ji
PDF
Completeness Modeling and Context Separation for Weakly Supervised Temporal Action Localization
Predictive Codingで用いた手法を動画にも適用した論文。動画の次の潜在表現を回帰で予測させてあげて,相互情報量の最大化を目指す。
Daochang Liu
PDF
Graphical Contrastive Losses for Scene Graph Parsing
シーングラフの生成において従来モデルの課題点を指摘した上で,それを改善するための新たなロスを提案し,SoTAを達成。
Ji Zhang
PDF
Code
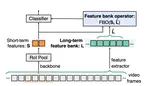
Long-Term Feature Banks for Detailed Video Understanding
3DCNNでは4秒近くにおける時系列情報しか捉えられない。そこでよりLongTermな情報と組み合わせて考えることでVideoRecognitionの精度が上がりましたよという論文。
Chao-Yuan Wu
PDF
MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation
行動認識のタスクにおいて,Temporal Convolutional Networksを複数重ねるMulti-TCNの提案。
Yazan Abu Farha
,
Juergen Gall
PDF
Code
Slides
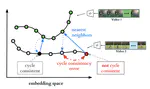
Temporal Cycle-Consistency Learning
異なる動画においても,同じ動作の場合特徴空間上で近くなるように学習させることで,似た動作の動画同士を同期できるようなマッチングを実現。
Debidatta Dwibedi
PDF
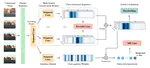
VideoBERT: A Joint Model for Video and Language Representation Learning
多くのモデルでVisionとLanguageでネットワークをそれぞれ用意して同時に学習させていた部分を,Bertを応用することでマルチモーダルに事前学習させる方法。
Jacob Devlin
,
Ming-Wei Chang
PDF
Neural Motifs: Scene Graph Parsing with Global Context
シーングラフ生成のタスクで既存のVisualGenomeデータセットにおける実験考察をもとに,新たにLSTMを用いた手法を提案。
Rowan Zellers
PDF
Code
»
Cite
×